En 2013, un grupo de agentes de la inteligencia británica notó algo
extraño. La mayoría de los esfuerzos para asegurar la infraestructura
digital se centraba en impedir que las incursiones de los hackers, pero había muy pocos proyectos dedicados a evitar que se filtrara la información. Sobre la base de esa idea, el grupo fundó una nueva empresa de ciberseguridad llamada Darktrace.
La compañía se asoció con matemáticos de la Universidad de Cambridge
(Reino Unido) para desarrollar una herramienta de aprendizaje automático
que detectara filtraciones internas. Pero, en vez de entrenar los
algoritmos con los ejemplos históricos de los ataques, necesitaban una estrategia para que el sistema reconociera nuevos casos de comportamiento anómalo. Así que se centraron el aprendizaje no supervisado,
una técnica basada en un extraño tipo de algoritmo de aprendizaje
automático que no requiere que los humanos especifiquen qué es lo que
habría que buscar.
Foto: Darktrace se ha centrado en un dispositivo infectado que presenta un comportamiento anómalo. Créditos: Darktrace.
“Es muy parecido al propio sistema inmunológico del cuerpo humano.
A pesar de ser algo tan complejo, tiene un sentido innato de lo que es
lo propio (el yo) y lo que es ajeno (el no-yo). Y cuando encuentra algo
que no es propio, el no-yo, tiene una respuesta extremadamente precisa y
rápida” explica la coCEO de la compañía, Nicole Eagan. .
La gran mayoría de las aplicaciones de aprendizaje automático se basan en el aprendizaje supervisado. Esto implica alimentar a una máquina con cantidades masivas de datos cuidadosamente etiquetados
para que aprenda a reconocer un patrón estrechamente definido. Digamos
que queremos que nuestra máquina reconozca a los perros de la raza
golden retriever. La alimentamos con cientos o miles de imágenes de
estos perros y de otras que no lo son, explícitamente indicando cuáles
son los que nos interesan. Finalmente, tendremos a una máquina bastante
decente para detectar la raza golden retriever.
En ciberseguridad, el aprendizaje supervisado funciona bastante bien.
Se entrena a una máquina sobre los diferentes tipos de amenazas que el
sistema ha enfrentado antes, y la máquina las persigue implacablemente.
Pero hay dos problemas importantes. Por un lado, esto solo funciona con las amenazas conocidas; las
amenazas desconocidas aún se cuelan por el radar. Por otro lado, los
algoritmos de aprendizaje supervisado funcionan mejor con conjuntos de
datos equilibrados; en otras palabras, con los que tienen una cantidad
igual de ejemplos de lo que se está buscando y de lo que se puede
ignorar. Los datos de ciberseguridad están muy desequilibrados: existen
muy pocos ejemplos de comportamientos amenazadores enterrados en una
cantidad abrumadora de comportamientos normales.
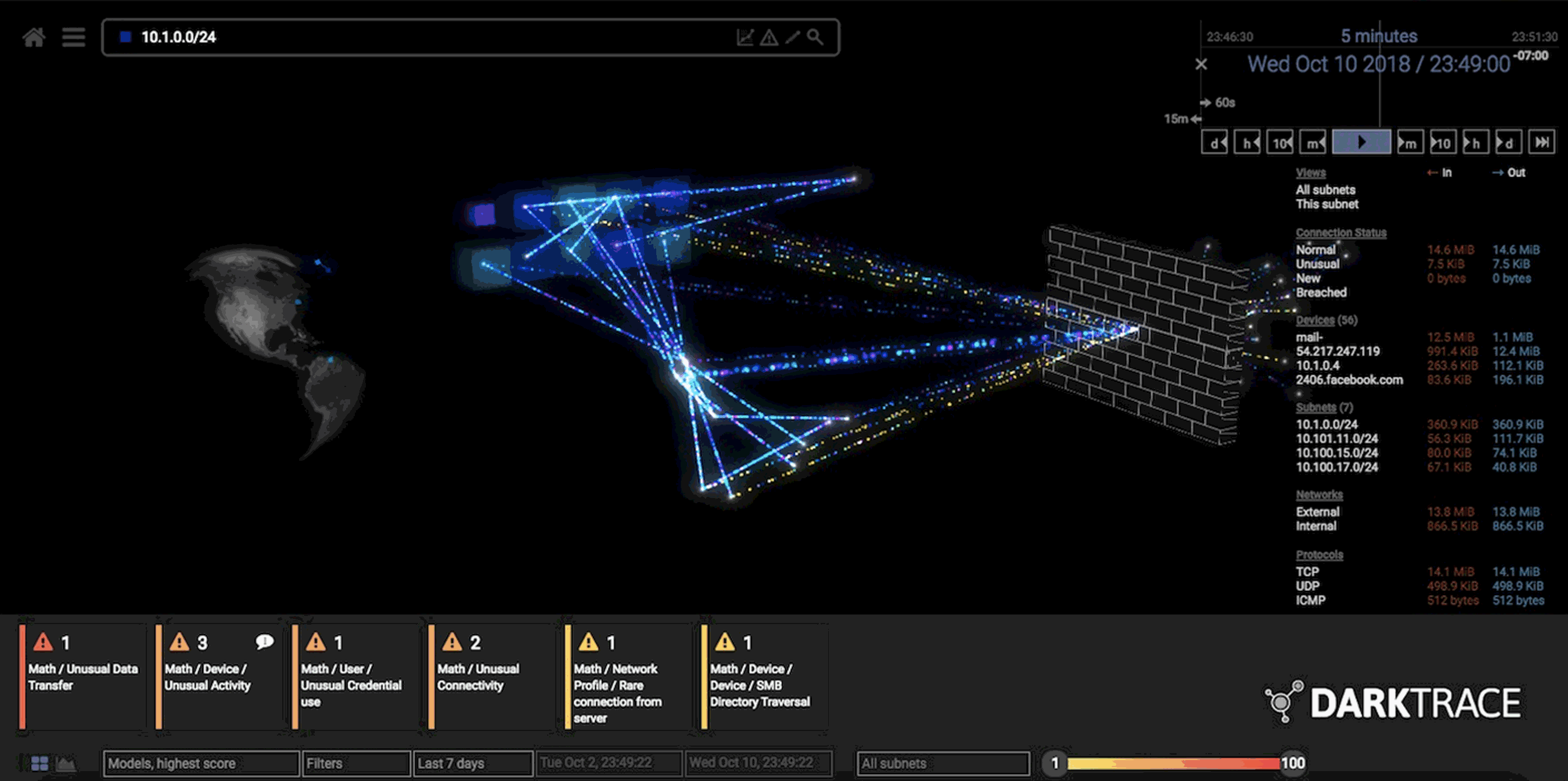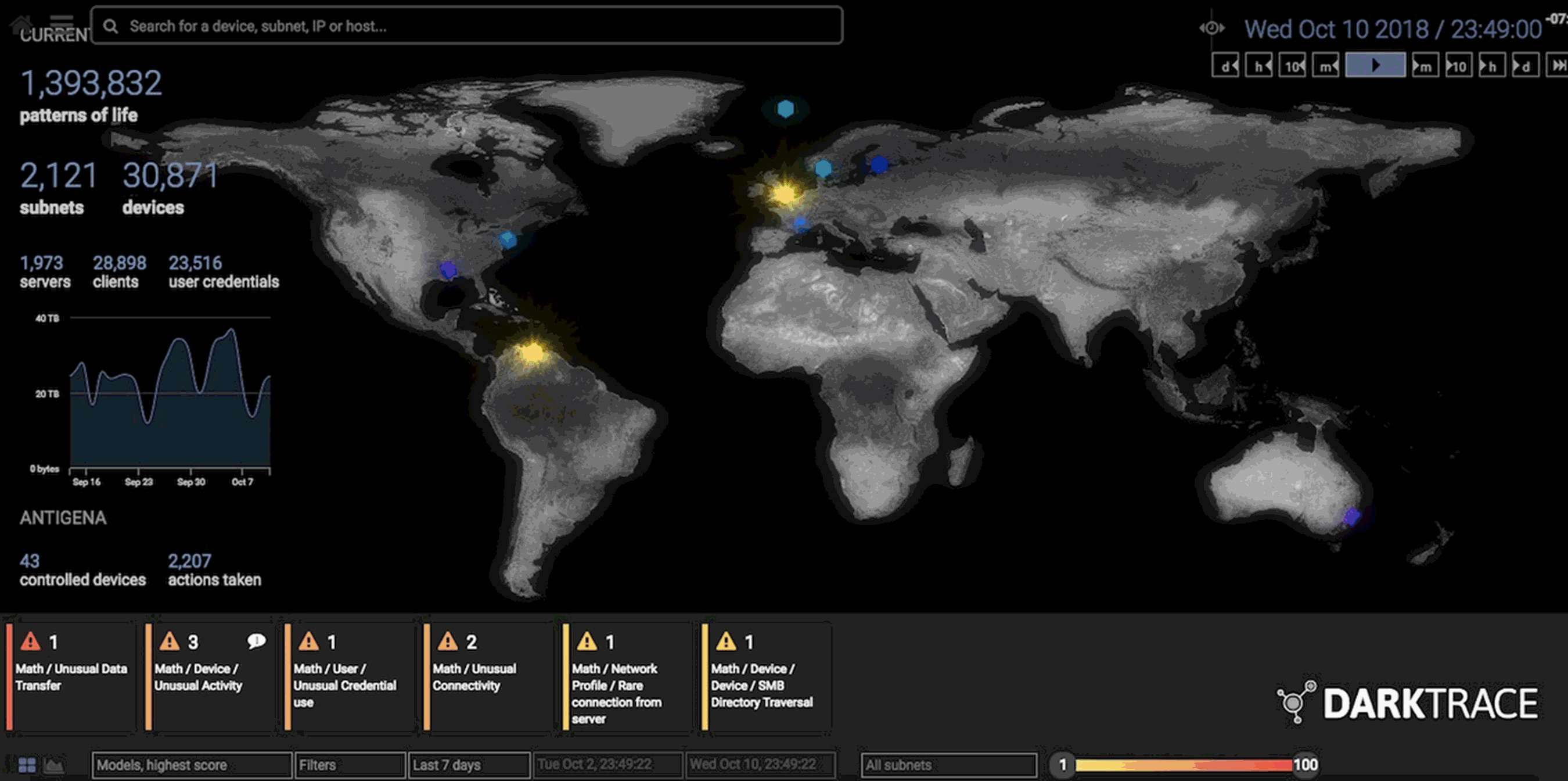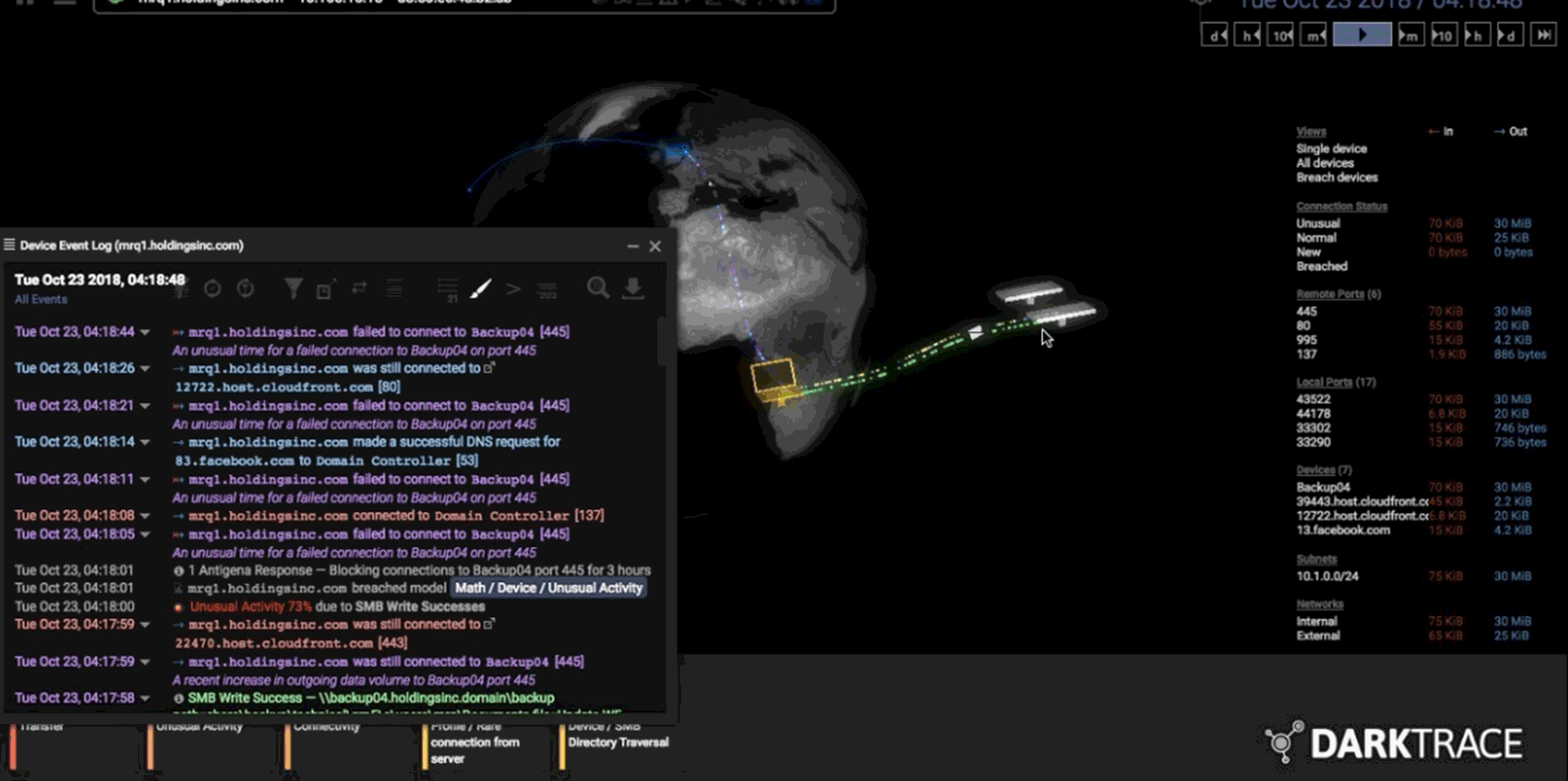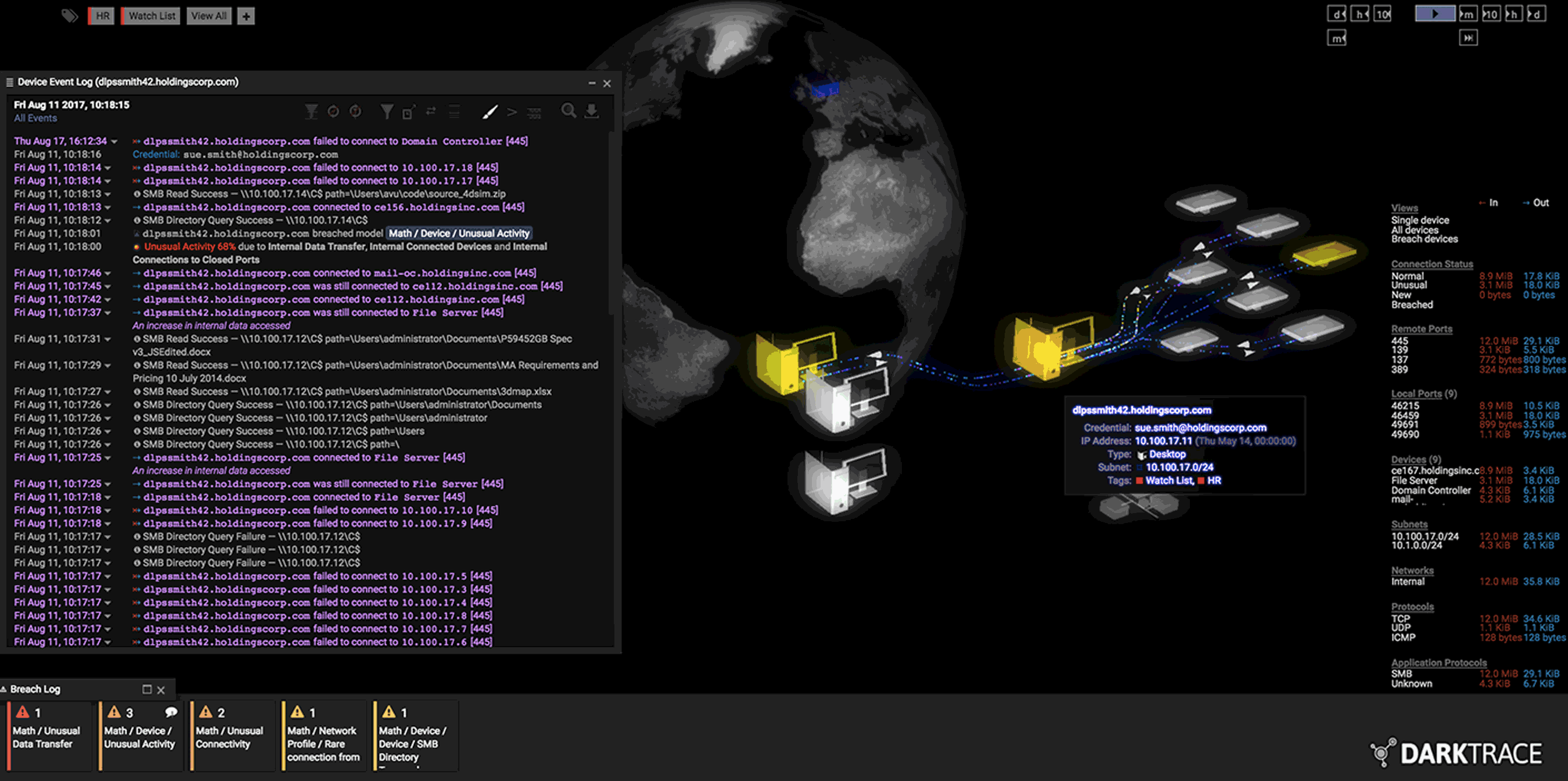
Foto: Una visualización de todas las conexiones dentro de una subred particular. Créditos: Darktrace.
Afortunadamente, donde el aprendizaje supervisado falla, el
aprendizaje no supervisado acierta. Este último puede ver cantidades
masivas de datos sin etiquetar y encontrar las piezas que no siguen un
patrón típico. Como resultado, puede descubrir amenazas que un sistema nunca había visto antes y solo necesita pocos puntos de datos anómalos para hacerlo.
Cuando Darktrace implementa su software, configura sensores físicos y
digitales alrededor de la red del cliente para trazar su actividad. Los
datos sin procesar se canalizan a más de 60 diferentes algoritmos de aprendizaje no supervisado que compiten entre sí para encontrar un comportamiento anómalo.
Esos algoritmos luego pasan sus resultados a otro algoritmo superior
que usa varios métodos estadísticos para determinar a cuáles de los 60
debe hacerles caso y a cuáles de ellos ignorar. Toda esa complejidad se
empaqueta en una visualización final que permite a los operadores
humanos ver posibles infracciones y responder rápidamente. Mientras los
humanos deciden qué hacer a continuación, el sistema bloquea la infracción hasta que se resuelva, cortando, por ejemplo, toda la comunicación externa del dispositivo infectado.
Sin embargo, no es oro todo lo que reluce en el aprendizaje no supervisado. A medida que los hackers aumentan sus habilidades, mejoran su forma de engañar a las máquinas,
independientemente del tipo de inteligencia artificial que se
aplique. “Se produce un juego del gato y el ratón en el que los
atacantes intentan cambiar su comportamiento”, explica la experta en
ciberseguridad y aprendizaje automático de la Universidad de California
en Berkeley (EE.UU.) Dawn Song.En respuesta, la comunidad de
ciberseguridad ha recurrido a enfoques proactivos: “mejores estructuras y
principios de seguridad para que el sistema esté más seguro en su
construcción”, afirma. Pero todavía hay un largo camino para erradicar
por completo todas las filtraciones y prácticas fraudulentas. Al fin y
al cabo, agrega, “todo el sistema es tan seguro como su eslabón más débil”.
La industria de lo no supervisado
Varias compañías también han optado por el aprendizaje no supervisado para mejorar los sistemas de seguridad digital.
Shape Security
Fundada en 2011 por exexpertos de Defensa del Pentágono, se centra en
prevenir la creación de cuentas falsas y el fraude de aplicaciones de
tarjetas de crédito, entre otras actividades maliciosas. Shape Security
combina los puntos fuertes complementarios de las técnicas supervisadas y
no supervisadas.
DataVisor
Fundada en 2013 por los exalumnos de Microsoft, se asocia con bancos, redes sociales y empresas de comercio electrónico para combatir el fraude de transacciones, el lavado de dinero y otros abusos a gran escala. DataVisor afirma que utiliza principalmente las técnicas no supervisadas.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duración
Descripción
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.

En 2013, un grupo de agentes de la inteligencia británica notó algo extraño. La mayoría de los esfuerzos para asegurar la infraestructura digital se centraba en impedir que las incursiones de los hackers, pero había muy pocos proyectos dedicados a evitar que se filtrara la información. Sobre la base de esa idea, el grupo fundó una nueva empresa de ciberseguridad llamada Darktrace.
La compañía se asoció con matemáticos de la Universidad de Cambridge (Reino Unido) para desarrollar una herramienta de aprendizaje automático que detectara filtraciones internas. Pero, en vez de entrenar los algoritmos con los ejemplos históricos de los ataques, necesitaban una estrategia para que el sistema reconociera nuevos casos de comportamiento anómalo. Así que se centraron el aprendizaje no supervisado, una técnica basada en un extraño tipo de algoritmo de aprendizaje automático que no requiere que los humanos especifiquen qué es lo que habría que buscar.
“Es muy parecido al propio sistema inmunológico del cuerpo humano. A pesar de ser algo tan complejo, tiene un sentido innato de lo que es lo propio (el yo) y lo que es ajeno (el no-yo). Y cuando encuentra algo que no es propio, el no-yo, tiene una respuesta extremadamente precisa y rápida” explica la coCEO de la compañía, Nicole Eagan. .
La gran mayoría de las aplicaciones de aprendizaje automático se basan en el aprendizaje supervisado. Esto implica alimentar a una máquina con cantidades masivas de datos cuidadosamente etiquetados para que aprenda a reconocer un patrón estrechamente definido. Digamos que queremos que nuestra máquina reconozca a los perros de la raza golden retriever. La alimentamos con cientos o miles de imágenes de estos perros y de otras que no lo son, explícitamente indicando cuáles son los que nos interesan. Finalmente, tendremos a una máquina bastante decente para detectar la raza golden retriever.
En ciberseguridad, el aprendizaje supervisado funciona bastante bien. Se entrena a una máquina sobre los diferentes tipos de amenazas que el sistema ha enfrentado antes, y la máquina las persigue implacablemente.
Pero hay dos problemas importantes. Por un lado, esto solo funciona con las amenazas conocidas; las amenazas desconocidas aún se cuelan por el radar. Por otro lado, los algoritmos de aprendizaje supervisado funcionan mejor con conjuntos de datos equilibrados; en otras palabras, con los que tienen una cantidad igual de ejemplos de lo que se está buscando y de lo que se puede ignorar. Los datos de ciberseguridad están muy desequilibrados: existen muy pocos ejemplos de comportamientos amenazadores enterrados en una cantidad abrumadora de comportamientos normales.
Afortunadamente, donde el aprendizaje supervisado falla, el aprendizaje no supervisado acierta. Este último puede ver cantidades masivas de datos sin etiquetar y encontrar las piezas que no siguen un patrón típico. Como resultado, puede descubrir amenazas que un sistema nunca había visto antes y solo necesita pocos puntos de datos anómalos para hacerlo.
Cuando Darktrace implementa su software, configura sensores físicos y digitales alrededor de la red del cliente para trazar su actividad. Los datos sin procesar se canalizan a más de 60 diferentes algoritmos de aprendizaje no supervisado que compiten entre sí para encontrar un comportamiento anómalo.
Esos algoritmos luego pasan sus resultados a otro algoritmo superior que usa varios métodos estadísticos para determinar a cuáles de los 60 debe hacerles caso y a cuáles de ellos ignorar. Toda esa complejidad se empaqueta en una visualización final que permite a los operadores humanos ver posibles infracciones y responder rápidamente. Mientras los humanos deciden qué hacer a continuación, el sistema bloquea la infracción hasta que se resuelva, cortando, por ejemplo, toda la comunicación externa del dispositivo infectado.
Sin embargo, no es oro todo lo que reluce en el aprendizaje no supervisado. A medida que los hackers aumentan sus habilidades, mejoran su forma de engañar a las máquinas, independientemente del tipo de inteligencia artificial que se aplique. “Se produce un juego del gato y el ratón en el que los atacantes intentan cambiar su comportamiento”, explica la experta en ciberseguridad y aprendizaje automático de la Universidad de California en Berkeley (EE.UU.) Dawn Song.En respuesta, la comunidad de ciberseguridad ha recurrido a enfoques proactivos: “mejores estructuras y principios de seguridad para que el sistema esté más seguro en su construcción”, afirma. Pero todavía hay un largo camino para erradicar por completo todas las filtraciones y prácticas fraudulentas. Al fin y al cabo, agrega, “todo el sistema es tan seguro como su eslabón más débil”.
La industria de lo no supervisado
Varias compañías también han optado por el aprendizaje no supervisado para mejorar los sistemas de seguridad digital.
Shape Security
Fundada en 2011 por exexpertos de Defensa del Pentágono, se centra en prevenir la creación de cuentas falsas y el fraude de aplicaciones de tarjetas de crédito, entre otras actividades maliciosas. Shape Security combina los puntos fuertes complementarios de las técnicas supervisadas y no supervisadas.
DataVisor
Fundada en 2013 por los exalumnos de Microsoft, se asocia con bancos, redes sociales y empresas de comercio electrónico para combatir el fraude de transacciones, el lavado de dinero y otros abusos a gran escala. DataVisor afirma que utiliza principalmente las técnicas no supervisadas.
Fuente
Compartir esto: